 MENU
MENU 

New generative AI model can reconstruct a high-quality, sparse-view 3D CT scan with a much lower X-ray dose
Although 3D CT scans offer detailed images of internal structures, the 1,000 to 2,000 X-rays captured at various angles during scanning can increase cancer risk for vulnerable patients. Sparse-view CT scans, which capture just 100 or even fewer X-ray projections, drastically reduce radiation exposure but create challenges for image reconstruction.
Recently, supervised learning techniques—a type of machine learning that trains algorithms with labeled data—have improved the speed and resolution of under-sampled MRI and sparse-view CT image reconstructions. However, labeling these large training datasets is time consuming and expensive.
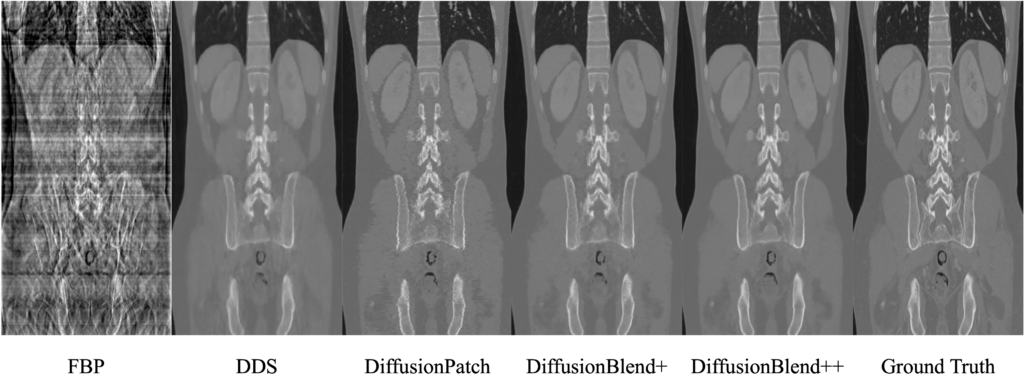
University of Michigan engineering researchers have led the development of a new framework called DiffusionBlend that can work efficiently with 3D images, making the method dramatically more applicable to CT and MRI.
DiffusionBlend uses a diffusion model—a self-supervised learning technique that learns a data distribution prior —to accomplish sparse-view 3D CT reconstruction through posterior sampling. The study was presented today at the Conference on Neural Information Processing Systems (NeurIPS) in Vancouver, British Columbia.
“Our new method improves speed and efficiency as well as reconstruction quality which is crucial for medical imaging,” said Bowen Song, a U-M doctoral student of electrical and computer engineering and co-first author of the study.
DiffusionBlend learns the spatial correlations among a group of nearby 2D image slices, called a 3D-patch diffusion prior, and then blends the scores of the multi-slice patches to model the entire 3D CT image volume.
When put to the test on a public dataset of sparse-view 3D CT scans, DiffusionBlend outperformed various baseline methods including four diffusion approaches at eight, six and four views with comparable or better computational image quality.
“Up to this point, the memory requirements and low computational efficiency of diffusion models has limited practical application. Our approach overcomes these hurdles, moving a step in the right direction,” said Liyue Shen, a U-M assistant professor of electrical and computer engineering and senior author of the study.
Further improving practicality, acceleration methods sped up the DiffusionBlend CT reconstruction time to one hour when previous methods took up to 24 hours.
Our new method improves speed and efficiency as well as reconstruction quality which is crucial for medical imaging.
Bowen Song, ECE doctoral student
“It was surprising how much you can speed up the process without sacrificing the quality of the reconstruction. That’s something we found very useful,” said Jason Hu, a U-M doctoral student of electrical and computer engineering and co-first author on the study.
Deep learning methods can introduce errors that cause visual artifacts—a type of AI hallucination that creates an image of something that’s not really there. When it comes to diagnosing patients, visual artifacts would quickly become a big problem.
The researchers suppressed visual artifacts through data consistency optimization, specifically using the conjugate gradient method, and measured how well generated images matched measurements with metrics like signal-to-noise ratio.
“We’re still in the early days of this, but there’s a lot of potential here. I think the principles of this method can extend to four dimensions, three spatial dimensions plus time, for applications like imaging the beating heart or stomach contractions,” said Jeff Fessler, the William L. Root Distinguished University Professor of Electrical Engineering and Computer Science at U-M and co-corresponding author of the study.
The authors acknowledge support from KLA and the Michigan Institute for Computational Discovery and Engineering (MICDE) Catalyst Grant and Michigan Institute for Data Science (MIDAS) PODS Grant.
Full citation: “DiffusionBlend: Learning 3D image prior through position-aware diffusion score blending for 3D computed tomography reconstruction,” Bowen Song, Jason Hu, Zhaoxu Luo, Jeffery Fessler, and Liyue Shen, The Thirty-Eighth Annual Conference on Neural Information Processing Systems (2024). DOI: 10.48550/arXiv.2406.10211