 MENU
MENU 

Gaining a deeper understanding of how personal values are expressed in text
Researchers used hierarchical trees to provide a better idea of how concepts are represented and related in a collection of text.
How much of what you value is reflected in what you post online? What do your Reddit posts say about your spirituality, or your concern for family and friends? Content analysis of large collections of text is often a useful first step in understanding what people are talking or writing about. It can help identify a person or group’s focus on emotional, political, or social themes, and even their core values. These are invaluable insights for social and information scientists.
PhD student Steve Wilson, Prof. Rada Mihalcea, and Master student Yiting Shen have proposed a new method of performing these analyses in their paper, “Building and Validating Hierarchical Lexicons with a Case Study on Personal Values.” The researchers earned a Best Paper Award at the 2018 International Conference on Social Informatics (SocInfo) for their work.
Current methods of identifying themes in these large bodies of text often involve building “topic models”, which statistically describe which groups of words often appear together in the same documents. However, these methods only provide general trends and do not allow researchers to explore specific concepts. To do that, a group of experts might use linguistic resources to compile a set of words that are known to be related to the phenomena they’re studying, but this often results in word lists with limited coverage.
To create larger, more inclusive lists, it is possible to use automatic methods to search for related terms and add these to the lists created by experts, but the newly added terms are prone to errors. It’s also possible to crowdsource the creation of massive lists of related words and concepts that appear in a collection of texts. This can be done by providing crowd workers with pre-determined lists of categories that they then set about grouping the text into, or allowing the categories to be created as sorting progresses for a more flexible approach.
These previous methods share one weakness – the lists they generate only offer limited coverage of the themes present in the text, and don’t give a good idea of how the different concepts are related to each other. Wilson, Shen, and Mihalcea’s project has replaced this list structure with a hierarchical tree structure to accomplish just that.
In their tree, any node can be represented by a combination of its descendent nodes. This allows modeling of hierarchical relationships between concepts, and offers researchers a configurable level of specificity when measuring concepts in the lexicon. For example, one researcher may want to measure positive emotions broadly, while another wants to keep track of more specific dimensions like excitement, admiration, and contentment. A well-built hierarchical lexical resource can cater to either, and, once formed, can be reused for different purposes depending on the research questions being asked.
Their approach to building these trees is crowd-sourced, and requires only a set of seed words that cover a variety of concepts within the theme. A theme could be anything from emotion to political discourse. The researchers also developed an evaluation framework that can be used to verify both the internal and external validity of the hierarchies developed by their method.
To go along with the paper, Wilson, Shen, and Mihalcea released a set of 50 value-related categories and lists of words and short phrases that belong to the categories. Users can use these lists to directly measure value-related content in texts, or use the team’s Python code to generate their own hierarchical lexicons for another topic with the support of workers from Amazon Mechanical Turk.
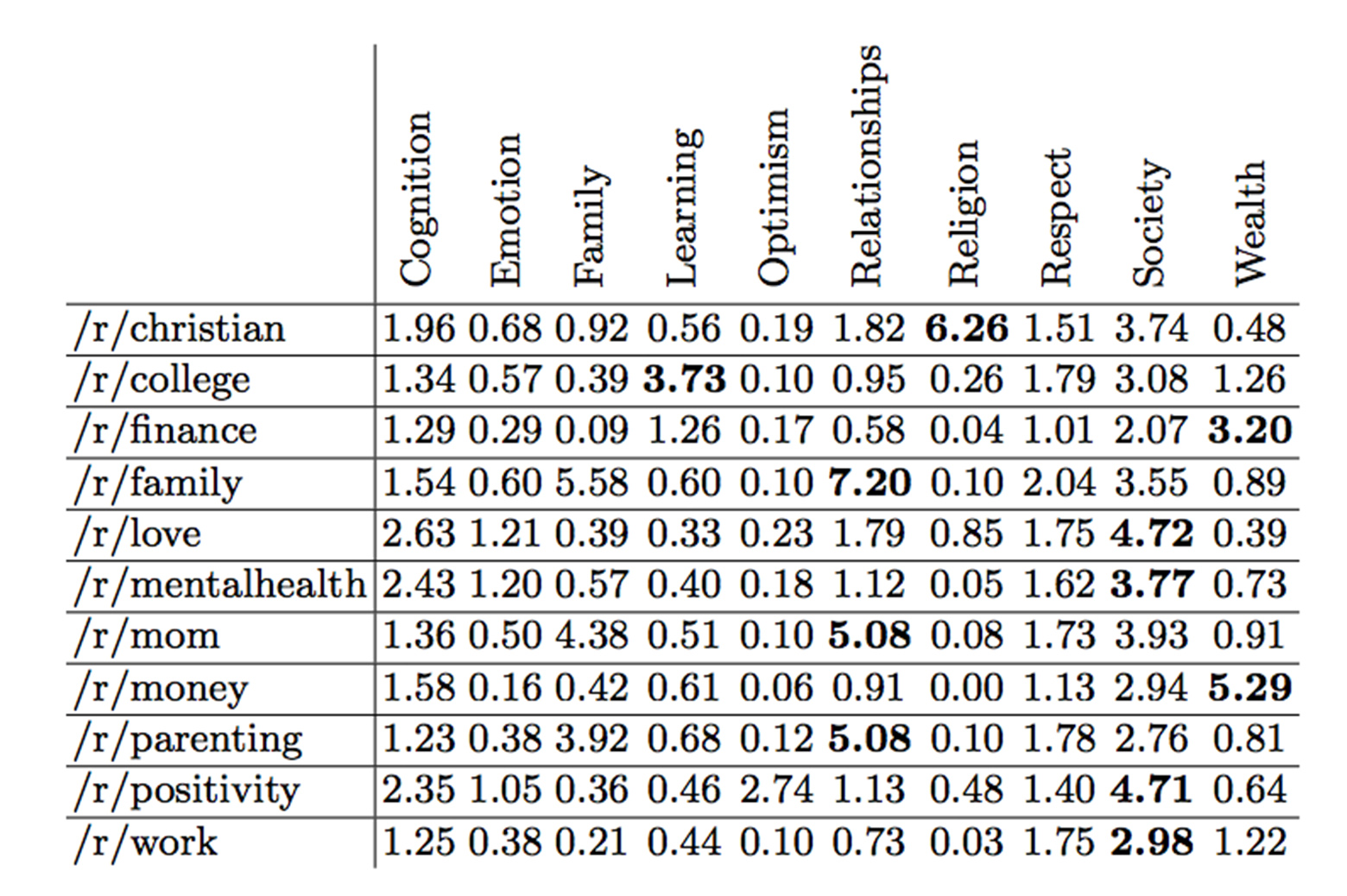
The researchers tested the functionality of their method with a collection of recent posts to different sub-forums on Reddit. They chose forums focused on topics expected to be related to personal values, like /r/christian and /r/money, and applied the lexicon to this text to verify that categories related to the community are more present than other categories.
 Enlarge
EnlargeMany of their results were validated by the data – the /r/christian forum used the most words found in the Religion category (like pray, jesus, and divinity), and the /r/money posts saw heavy use of words in the Wealth category (including revenue, wage, and cash).
The paper was presented at the 10th SocInfo Conference on September 28th in St. Petersburg, Russia.