 MENU
MENU 

Designing a flexible future for massive data centers
A new approach recreates the power of a large server by linking up and pooling the resources of smaller computers with fast networking technology.

 Enlarge
EnlargeThe days of bulky, expensive servers filling up data centers may be numbered. Michigan computer scientists are pursuing a new paradigm in server design that promises to offer a cheaper and more reliable means of processing the many millions of requests these huge data centers handle every day. Called rack-scale computing, this approach recreates the power of a large server by linking up and pooling the resources of smaller computers with fast networking technology.
Rack-scale computing has been the focus of several projects led by Profs. Mosharaf Chowdhury and Barzan Mozafari. Piece by piece, their research teams are working to make the experience of interacting with a rack of computers feel as seamless as accessing a single traditional server.
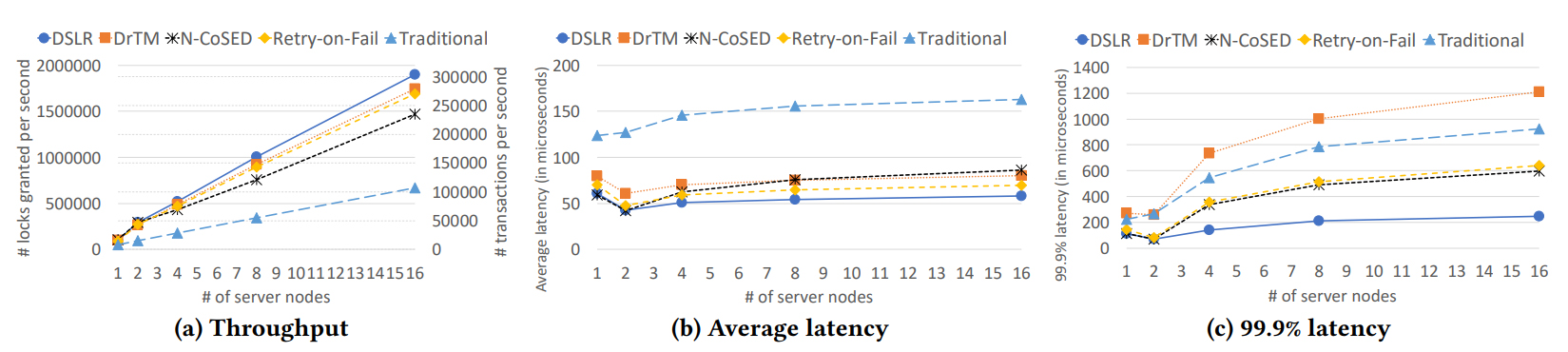
One of the pair’s recent projects with grad student Dong Young Yoon, an algorithm called “Decentralized and Starvation-free Lock management with RDMA” (DSLR), tackles the problem of granting many users access to a rack’s shared memory simultaneously. Their solution takes advantage of Remote Direct Memory Access (RDMA), a technology that allows computers to read and write to memory on a different machine without interrupting the CPU, and is uniquely designed to work with the distributed nature of rack-scale systems.
The principle goal of rack-scale design is to be able to treat components spread across many different computers as one huge “abstract computer.” As a user, you shouldn’t be able to tell the difference between interacting with a single super-powered server and a “server” comprised of dozens of networked, disaggregated computer parts collectively working on your task.
“Right now every server has a CPU, memory, and a disk – we are trying to disaggregate these from each other,” Chowdhury explains. “Then you aggregate all the memory together and all the disks together – make it look like all of the memory is a single pool, even when physically it is separated.”
While the user shouldn’t have to know the difference, the data centers providing these services can get more flexibility and better performance for significantly less cost when they go the rack-scale route. Rather than adding or replacing an expensive server, data centers are free to independently upgrade computation, network, and storage systems as needed. At a time when the demand for computing power and data storage capacity is growing by as much as 30-40 percent per year, this flexibility can be vital.
On top of that, disaggregating the components makes system failures far less disastrous – gone would be the days of users losing service entirely when a machine goes down.
“When you have an array of 40-ish machines and a few of them fail, I can hide them and you don’t have to change anything,” Chowdhury says. “All the failures can be handled fully transparently.”
Many challenges arise in connecting computers together as a shared resource, especially at the scale of data centers with millions of users. Handling all of those requests in parallel requires a re-think of how memory is accessed to prevent users from coming into conflict.
“Whenever you have massive degrees of parallelism, whether they are multiple processes, or transactions, you need to rethink your method of synchronization,” Mozafari says. To find a solution, Mozafari drew on his experience in designing low-latency transactional systems, an area that offers insight into granting data access to many users.
Traditionally, databases that juggle multiple users have relied on locking to prevent possible conflicts. When one process grabs a resource, you lock it down until the process is done. But straightforward, classical lock managers are too costly and time-consuming for applications that put RDMA to use, which typically demand extremely low latency.
Instead, DSLR implements a distributed “bakery algorithm,” modeled after taking a number at a bakery rather than waiting in a line. This suits the decentralized nature of a rack-scale environment, as every user can keep their own counter and use some of the built-in operations RDMA offers to check when their number is up.
In this version of the algorithm, every user is given a lease when they access a block of memory. They’re able to use that memory for a set amount of time, and if they don’t finish their process before the deadline they’re booted out for the next user and must wait their turn again.
“On the scale of millions of concurrent transactions, it turns out decentralization is just the right thing to do,” says Mozafari. “You occasionally kick out a transaction that outstays its lease, and let the others go ahead – this lends itself to a fully distributed, fully decentralized protocol that can exploit a modern network’s hardware.”
“No one is spending too much time doing anything, no one is getting any special treatment, and no one is starving or waiting forever for someone else to leave,” says Chowdhury.
The researchers’ experiments show that DSLR delivers up to 2.8X higher throughput than all existing RDMA-based lock managers, while reducing their average and slowest latencies by up to 2.5X and 47X, respectively.
 Enlarge
EnlargeFor Chowdhury, this project was a natural step forward from his recent major work, software called Infiniswap, that improved memory utilization in a rack or cluster by up to 47 percent.
“What Infiniswap tried to do was make the RAM that is spread across many different machines look like one big block of RAM,” says Chowdhury. This work focused on how a single user could use RDMA to treat disaggregated memory as one resource; now, with locking, he and Mozafari are working to make that ecosystem accessible by many users at once.
Of course, memory is just one part among many needed by large-scale services. Students in Chowdhury’s group are working to disaggregate graphics processing units (GPUs) in the same way. GPUs have turned out to be particularly good at running machine learning (ML) algorithms, making this project particularly helpful to ML researchers who currently have to develop a deep understanding of GPU functionality to optimize their programs. Giving them the power of many GPUs functioning as a large, abstract component would remove that burden.
Other students are working on developing a file system that would exist over memory on an RDMA system, allowing users to store and access data intuitively even when working with components spread across several machines.
Together, all of these components point to a future where servers can become more than the sum of their parts.
“In a rapidly evolving market, like what we see today for distributed and cloud computing, sometimes you just have to go back to the drawing board and question some of the traditional wisdoms that make a lot of sense for the hardware we had two decades ago,” says Mozafari. “We’re living at an age where today’s greatest technology may be considered outdated in a matters of months.”