 MENU
MENU 

CSE researchers win Outstanding Paper Award at ACL 2023
CSE PhD student Ziqiao “Martin” Ma, and CS undergraduate student Jiayi Pan, and Prof. Joyce Chai have been selected as recipients of the Outstanding Paper Award at the 2023 Annual Meeting of the Association for Computational Linguistics (ACL). They were recognized by the conference for the excellence of their paper World-to-Words: Grounded Open Vocabulary Acquisition through Fast Mapping in Vision-Language Models, which explores grounded word learning in a newly developed vision-language model.
ACL 2023, which took place July 9-14 in Toronto, Canada, is the preeminent international venue for the latest research on computational linguistics and natural language processing. Only a select few papers, comprising less than 1% of total submissions to the conference, are honored with the Outstanding Paper Award. Papers are chosen based on their exceptional quality and impact on the broader field.
Grounding, the ability to tie new words to referents in the real world, is a key component of language learning. For humans, this grounding is a relatively easy task that allows us to learn new words based on context. There have been growing efforts to equip artificial intelligence (AI) systems with similar abilities, enabling them to learn and understand the meaning of new words with minimal supervision.
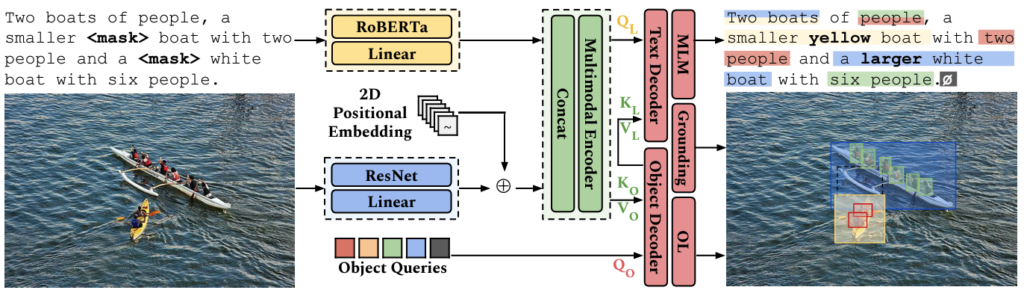
To better facilitate grounded vocabulary acquisition, CSE researchers have developed a novel object-oriented, visually grounded language model called OctoBERT. OctoBERT acquires its ability to ground new words during pre-training with image-text pairs. It is then able to replicate this ability in the absence of grounding supervision, learning the grounded meanings of new words both seen and unseen. OctoBERT functions much as humans do, using visual and linguistic context to predict and ground missing words.
Extensive testing revealed that OctoBERT outperformed other vision-language models on grounded word acquisition tasks with substantially less data. The grounding ability it acquires during pre-training enables OctoBERT to learn unseen words more quickly and accurately than comparable models.
This ability to learn new vocabulary based on context opens up new avenues for open-world language learning among AI agents, a major advance in the development of intelligent AI systems.